크롤러란?
내가 생각하기에 크롤링이란.. 원하는 정보를 캐내는 작업이라고 생각한다. crawler란 기어가는 사람 혹은 포복 동물이라는 의미인데, 사실 왜 기어다닌다고 표현하는지 감이 안온다.. 왜지?! 언뜻 보면 마이닝(mining)과 같은 것이라고 생각이 되긴 하는데, 내 생각에 큰 차이점은 크롤링은 완전한 raw 데이터에서 정보를 추출한 것이고, 마이닝은 추출한 무작위 정보들을 바탕으로 더욱 더 유용하고 실용적인 정보로 나아가는 것이라고 생각한다.
어쨌거나 저쨌거나 요즘과 같은 데이터시대에서 유용한 데이터로 만드는 것이 관건인데, 그중 베이스중에 베이스 (콜미 베베) 인 것이 바로 이 크롤링이 되시겠다.
웹에서 정보 가져오기
Requests
Python에는 requests라는 http request 라이브러리가 있다.
설치하기
1 | |
커맨드창에서 저렇게 pip로 간단하게 설치하면 된다! (팁아닌 팁이자면.. 나중에 requirements.txt 파일에 저 requests 라이브러리를 추가해준 후 한꺼번에 다운로드 할 수 있게 하면 굳!)
이용 방법
아래와 같이 파이썬 파일을 하나 만들어 requests를 import 한 후 사용한다.
1 | |
우리는 웹을 크롤링 하는 것이기 때문에 주로 HTML 소스를 사용한다. 따라서 html = req.text를 꼭꼭 알고 있어야 한다!
BeautifulSoup
Requests로 불러온 html 코드에서 ‘의미있는’ 정보를 추출할 수 있게 도와주는 라이브러리다. 이 BeautifulSoup은 html 코드를 python이 이해하는 객체 구조로 변환하는 파싱을 맡고있다.
설치하기
1 | |
마찬가지로 커맨드창에서 실행한다!
이용 방법
위의 코드에서 살짝 변형을 하자면,
1 | |
이제 soup 객체에서 원하는 정보를 찾아낼 수 있다.
BeautifulSoup에서는 여러가지 기능을 제공하는데, 여기서는 select를 이용한다. select는 CSS Selector를 이용해 일치하는 모든 객체들을 List로 반환해준다.
예시로, 내 깃허브 레포지토리들의 타이틀들을 가져와보도록 하자.
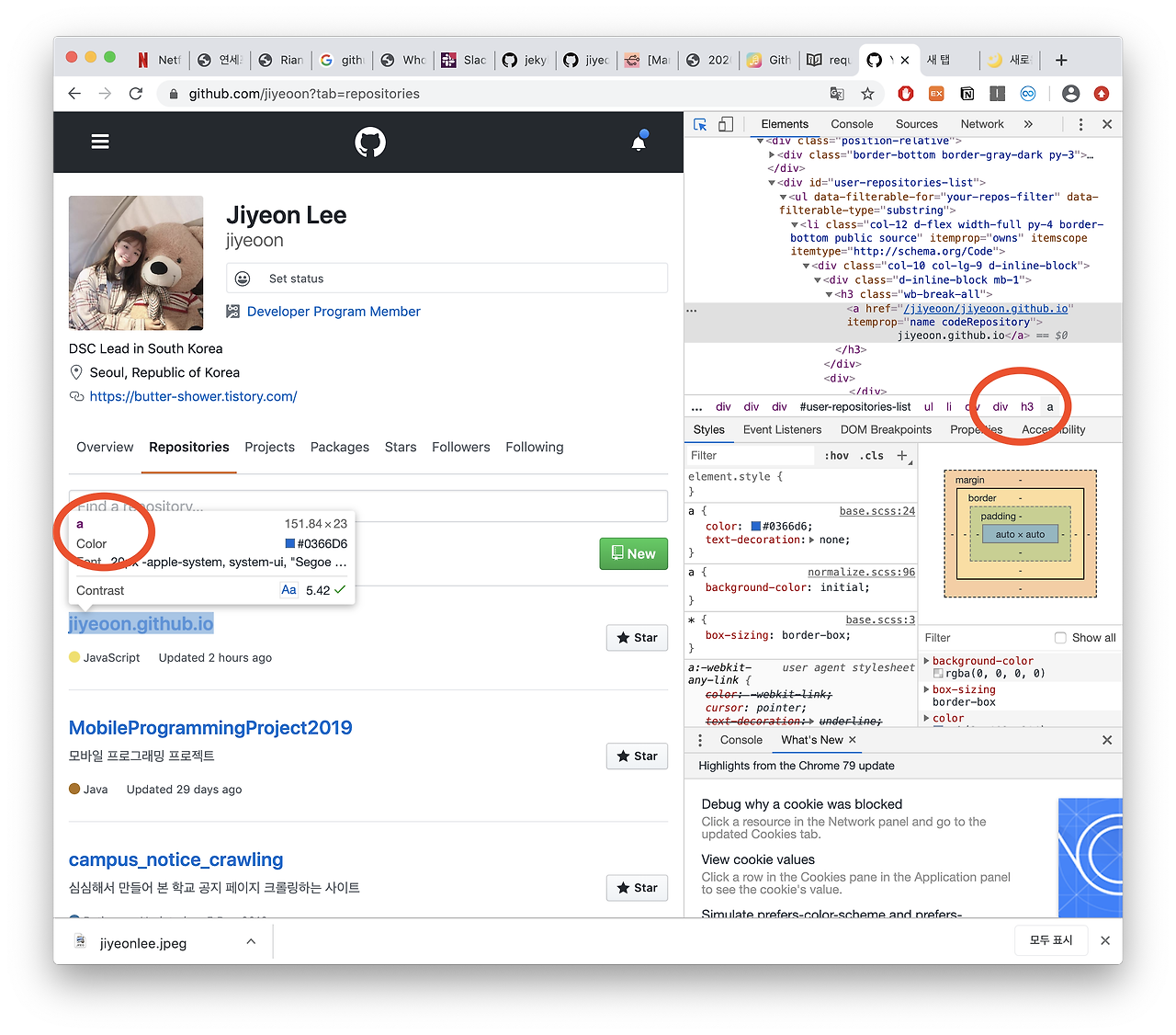
크롬 개발자 도구로 확인을 해보면, 저렇게 어쩌구 저쩌구.. div 안에 div 안에 div.. 하다가 h3 그리고 a가 뜬다. 그럼 select 할 때 h3 아래의 a 의 내용들을 모두 가져오겠다고 하면 되겠지?!
1 | |
결과를 확인해보면
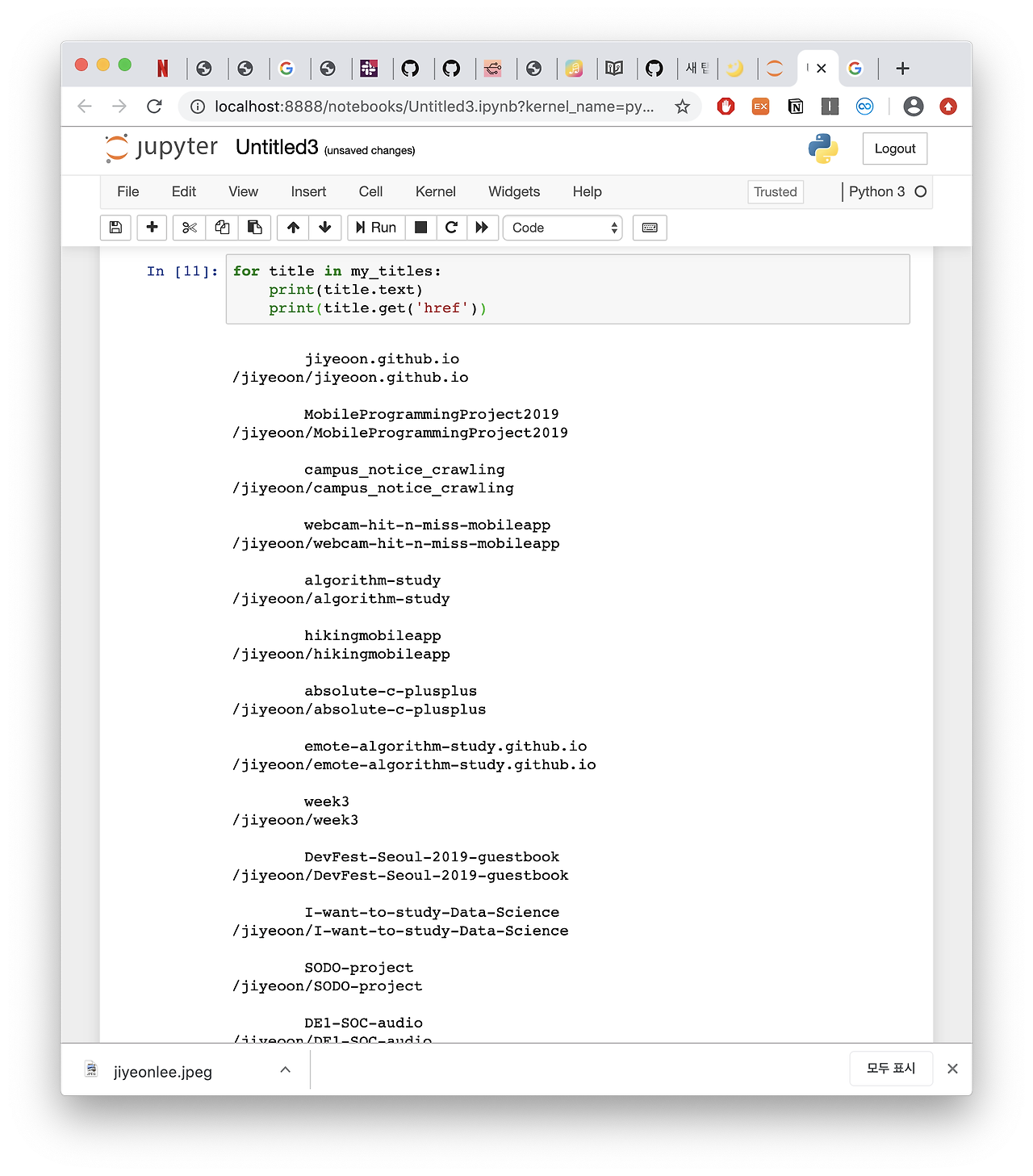
잘 된다~~ ㅎㅅㅎ
Reference
https://beomi.github.io/gb-crawling/posts/2017-01-20-HowToMakeWebCrawler.html